Por Ricardo Eíto Brun
Por Ricardo Eíto Brun
Ricardo Eíto Brun, experto en aseguramiento de la calidad, ontologías y metadatos, desempeña su actividad profesional en el área de I+D de Meta4 Software (Madrid).
Foto: CC BY Tomàs Baiget
Como resultado del increíble crecimiento y progresiva monopolización que el WWW está ejerciendo sobre Internet, se han propuesto distintos mecanismos capaces de superar las limitaciones de los sistemas de recuperación de información basados en la navegación hipertexto.
Las propuestas se han materializado en tres grandes líneas de trabajo:
a) Índices compilados ‘manualmente’, que organizan la información de acuerdo con algún tipo de clasificación jerárquica: Yahoo, IBC Sleuth, The Mother of All the Bulletin Boards, etc.
b) bases de datos creadas automáticamente por ‘robots’ o ‘arañas’, y
c) métodos de indización distribuida, en los que cada servidor web crea un índice de sus propios recursos, que posteriormente engrosará una base de datos centralizada sobre la que podremos lanzar nuestras ecuaciones de búsqueda (Aliweb o Harvest).
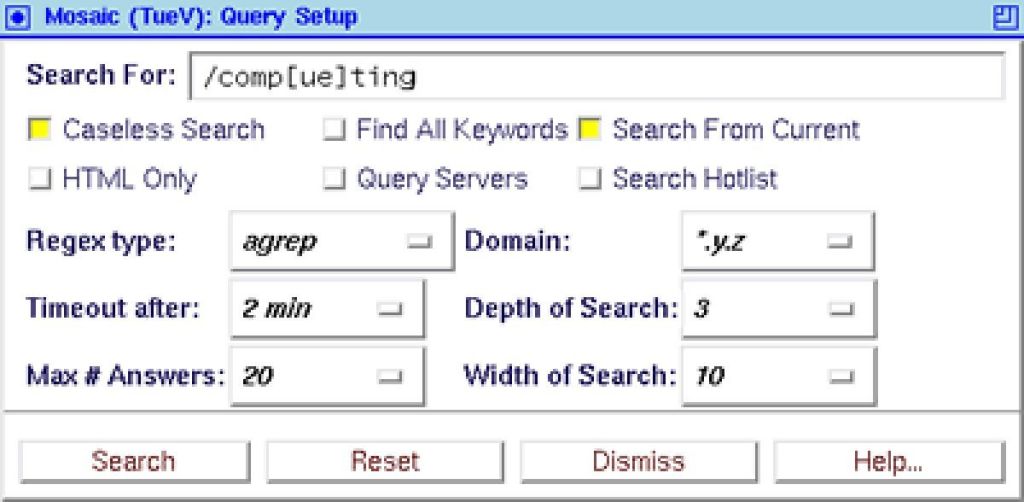
Nuevo rol del cliente en la recuperación de información
Como contrapartida a estos sistemas han surgido los denominados ‘robots personales’. Este tipo de aplicaciones aparecen integradas con el cliente web y ofrecen una funcionalidad supuestamente similar a la de los robots reseñados en el párrafo anterior.
El primer problema que encontramos al tratar este tema es el de una manifiesta inconsistencia terminológica: con este término se designa un conjunto de herramientas que sirven para distintos propósitos. ¿Qué características debe ofrecer una aplicación para denominarse ‘robot personal’?
La definición clásica de ‘robot’ es la de un agente que recorre de forma automática la WWW con distintos fines: análisis del crecimiento de la red, mantenimiento de la estructura hipertexto, duplicación de directorios y elaboración de bases de datos que permitan acceder directamente a recursos informativos mediante palabras clave.
El rasgo característico de un robot es su capacidad de explotar, para cualquiera de estos propósitos, la estructura hipertextual del web. Así, tomando como punto de partida una URL inicial, el robot recupera un fichero html que transfiere al sistema local de forma similar a como lo hace un cliente web; pero, una vez recuperado, en lugar de proceder a su visualización, se servirá de él para generar recuentos estadísticos, engrosar un índice sobre el que ejecutar búsquedas, etc.
Tras esto, el robot identifica las referencias hipertextuales que contiene el documento y que dirigen a otras unidades informativas en el mismo o en otros servidores de la red; de forma recursiva, el robot procede a recuperar los documentos referenciados en esos nexos, a su tratamiento, obtención de nuevas URLs, etc.
Podemos concluir que la ‘navegación automática’ es el rasgo distintivo de un ‘robot’, y que cualquier software que pretenda tildarse como ‘robot personal’ deberá ser capaz de proceder de esta forma. Sin embargo, no todas los programas así denominados comparten esta característica; en las siguientes líneas describiremos cinco aplicaciones de este tipo, dos de ellas desarrolladas con fines comerciales.
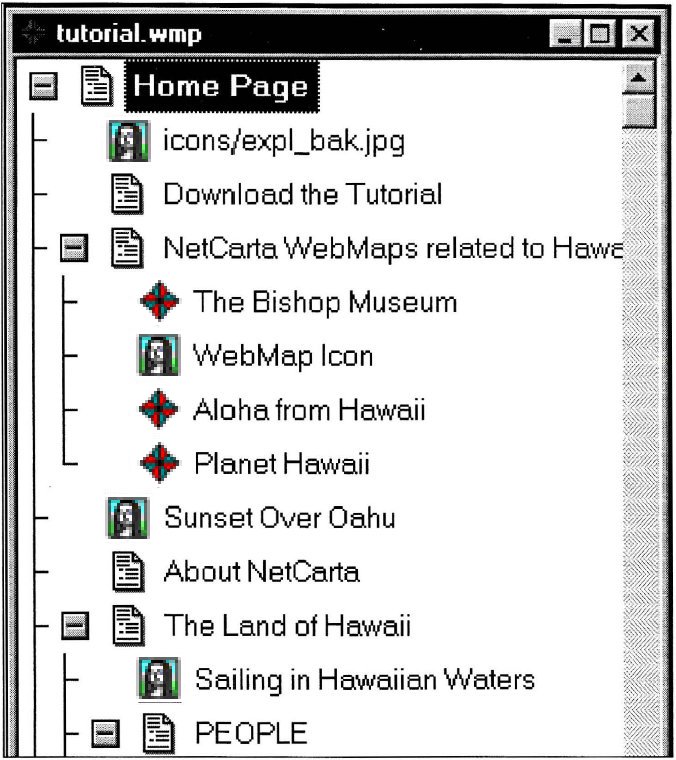
Ejemplo de mapa creado por CiberPilot.
Los objetos se estructuran jerárquicamente, y cada uno aparece identificado por un icono y una leyenda. EI botón gris que aparece a la izquierda del icono puede mostrar tres estados:
- un signo +, si el objeto referencia a otros objetos que no son visibles en ese momento;
- un signo –, si la jerarquía de objetos dependientes está desplegada o visible;
- un signo ?, indicador de que el objeto no ha sido explorado por CiberPilot.
EI color de la leyenda podrá ser:
- negro, cuando el objeto referenciado se encuentre en el mismo servidor;
- azul, si el objeto reside en otro host;
- verde, cuando referenciamos un objeto que ya ha sido mencionado (ruta alternativa); o
- rojo, caso en el que CiberPilot no ha podido recuperar un objeto, pudiendo tratarse de un enlace hipertextual erróneo.
CiberPilot Pro
Es un producto de NetCarta Corporation que posibilita la creación de mapas de los servidores WWW. Es decir, como resultado de su acción, CiberPilot genera un fichero con extensión .wmp (WebMap) en el que se representa la estructura hipertextual de las páginas recogidas en un servidor. De esta forma, el usuario podrá servirse de estos mapas para acceder a los recursos disponibles en él mediante una única conexión, eliminando la navegación hipertexto. Sin embargo, si se opta por ésta en lugar de por un acceso directo, los mapas de CiberPilot actúan como guía de la estructura del servidor, evitando el principal problema de la recuperación en entornos hipertexto: perdernos en la información.
Un mapa CiberPilot presenta una estructura jerárquica de iconos, cada uno de ellos con su respectiva leyenda. El tipo de icono variará dependiendo del recurso referenciado en la página web (imagen, sonido, referencia a una página externa, dirección de correo electrónico, etc.).
Por otra parte, las leyendas equivaldrán al texto comprendido entre las etiquetas <title> y </title> si el recurso referenciado es una página html; al texto especificado tras el atributo atl en el caso de una imagen; etc. No obstante, existe la posibilidad de modificar en cualquier momento las leyendas asociadas a un icono.
Ejemplo: Al mapa de la imagen anterior le corresponden varias páginas html. La primera, en un primer nivel de jerarquía, contendrá las siguientes referencias:
<html>
<title>Home Page</title>
<body>
<img src=»icons/expl_bak.jpg»>
<a href=»tutorial.html»>Download the tutorial</a>
<a href=»hawaymap.html»NetCarta Webmaps related to Haway</a>
<img src=»icons/sunset.jpg» alt=»Sunset over Oahu»>
<a href=»about.html»>About NetCarta</a>
…………
</body>
</html>
Para elaborar un mapa deberemos indicar a CiberPilot la URL del servidor, así como una serie de parámetros que especifiquen cuántos ficheros html deseamos examinar, con qué profundidad deberá procederse en la búsqueda (CiberPilot utiliza una recuperación ‘breadth first’), y si queremos habilitar la navegación entre distintos servidores una vez se encuentre una referencia a un fichero residente en otro host.
Creado un mapa, podremos hacer uso de él a través de CiberPilot, que arrancará el cliente web siempre que deseemos abrir la conexión con cualquiera de los recursos reseñados en sus mapas.
Otro aspecto interesante es que CiberPilot implementa un sistema similar al protocolo de exclusión de robots (que por cierto también respeta), el cual le posibilita reconocer si un servidor ha sido visitado con anterioridad por otro robot CiberPilot. Para ello, el administrador del servidor deberá contar con un mapa de sus propios recursos, el fichero default.wmp, al que se hará referencia en la hoja principal mediante:
<a href=»/directorio/default.wmp»>NetCarta WebMap</a>
CiberPilot, al identificar la presencia de este fichero, lo recuperará y finalizará su interacción con el servidor.
Obviamente, para que todo esto sea posible, siempre que se cree un nuevo mapa de un servidor, deberá enviarse a su administrador el fichero resultante, para que éste pueda incluir el enlace pertinente si lo considera oportuno.
Finalmente indicaremos que se han creado directorios de mapas CiberPilot para que sus usuarios puedan compartir el resultado de su trabajo; así, podemos encontrar ‘webmaps’ en:
- NetCarta Corporation: http://www.netcarta.com
- GeoCities: http://www.geocities.com
- Lycos: http://www.lycos.com
- Point Communications: http://www.pointcom.com
Simon (System of Internet Mapping for Organised Navigation)
Es un programa de Mark Johnson en el Queen Mary and Westfield College de la University of London. Aunque Simon aparece referenciado en ocasiones como un ‘robot personal’, nos resistimos a aceptar esta designación.
El funcionamiento de Simon puede sintetizarse de la siguiente forma: permite crear una agenda de URLs a las que se asocia una serie de palabras clave que facilitarán su recuperación; posteriormente, tomando como base la información consignada en la agenda, un procedimiento algorítmico genera un ‘mapa’, más concretamente una estructura arborescente, de los ‘espacios conceptuales’ especificados por las palabras clave.
El ‘mapa’ consiste en una hoja html en la que, bajo cada materia, se enumeran las URLs donde se trata ese tema.
Obviamente constituye un abuso terminológico designar a Simon como un ‘robot personal’; de hecho, la denominación más acertada y acorde con su funcionalidad sería la de un ‘gestor de URLs’.
Se puede encontrar más información en:
http://www.elec.qmw.ac.uk:80/simon
TkWWW Robot Integra un visualizador o cliente web con un robot personal. De hecho, TkWWW comenzó siendo un visualizador distribuido libremente en Internet, al que posteriormente su autor, Scott Spetka (en la foto), añadió una mayor funcionalidad que le permite ser reconocido como un auténtico ‘robot personal de primera generación’.
Integra un visualizador o cliente web con un robot personal. De hecho, TkWWW comenzó siendo un visualizador distribuido libremente en Internet, al que posteriormente su autor, Scott Spetka (en la foto), añadió una mayor funcionalidad que le permite ser reconocido como un auténtico ‘robot personal de primera generación’.
Aunque la principal orientación de TkWWW es la recuperación de información (configurando una base de datos local), puede desempeñar cualquiera de las funciones propias de un robot, ya que su funcionamiento se basa en una serie de extensiones programables por el usuario en lenguaje TCL (tool command language, lenguaje para desarrollo en sistemas Unix); así, TkWWW constituye un entorno abierto a tantos usos como podamos imaginar, por lo que Spetka no duda en referirse a él como un ‘robot de propósito general’.
Técnicas de navegación en entornos hipertexto
Establecemos la distinción entre búsquedas ‘breadth-first’ y ‘depth-first’.
En el primer caso, se exploran todos los nodos referenciados en el documento actual. Estos nodos se encuentran en un mismo nivel de jerarquía. Seguidamente, se exploran los nodos referenciados en los nodos anteriores, descendiendo un único nivel, etc.
En una búsqueda ‘depth-first’, cada vez que se recupera un nuevo nodo, se procede a explorar los nodos referenciados en él descendiendo por la jerarquía tantos niveles como consideremos oportuno.
Fish-Search
 Es un sistema integrado en el cliente X-Mosaic desarrollado por Paul M. E. de Bra (izquierda) y Reinier D. J. Post (derecha) en la Eindhoven University of Technology. Su principal característica es que hace la recuperación de documentos de forma similar a un robot tradicional, aunque su objetivo no es la creación de una base de datos local, sino la navegación automática, recuperando documentos html afines a un patrón de búsqueda propuesto inicialmente por el usuario.
Es un sistema integrado en el cliente X-Mosaic desarrollado por Paul M. E. de Bra (izquierda) y Reinier D. J. Post (derecha) en la Eindhoven University of Technology. Su principal característica es que hace la recuperación de documentos de forma similar a un robot tradicional, aunque su objetivo no es la creación de una base de datos local, sino la navegación automática, recuperando documentos html afines a un patrón de búsqueda propuesto inicialmente por el usuario.
Los autores se refieren al sistema con esta metáfora:
«Nuestro algoritmo de búsqueda se basa en la metáfora de los bancos de peces: un banco de peces se mueve en dirección a la comida. Mientras nadan, los peces también se reproducen. El número de crías y su fuerza dependen en gran medida de la cantidad de alimento que encuentren. El banco se divide regularmente cuando encuentra alimento en diferentes direcciones. Los peces individuales o partes del banco que se dirigen hacia una dirección donde no hay alimento morirán de hambre. Los peces o partes del banco que entran en aguas contaminadas también mueren».