Por Lluís Codina

Lluís Codina Bonilla es profesor de Documentación en el Departament de Comunicació de la Universitat Pompeu Fabra, Barcelona.
Foto: CC BY Tomàs Baiget
La especialidad del programa ZyIndex consiste en la creación de sistemas documentales a partir de la indización automática de documentos y en la potencia de su lenguaje de interrogación, que permite crear subconjuntos muy selectivos de documentos a partir del contenido de los mismos.
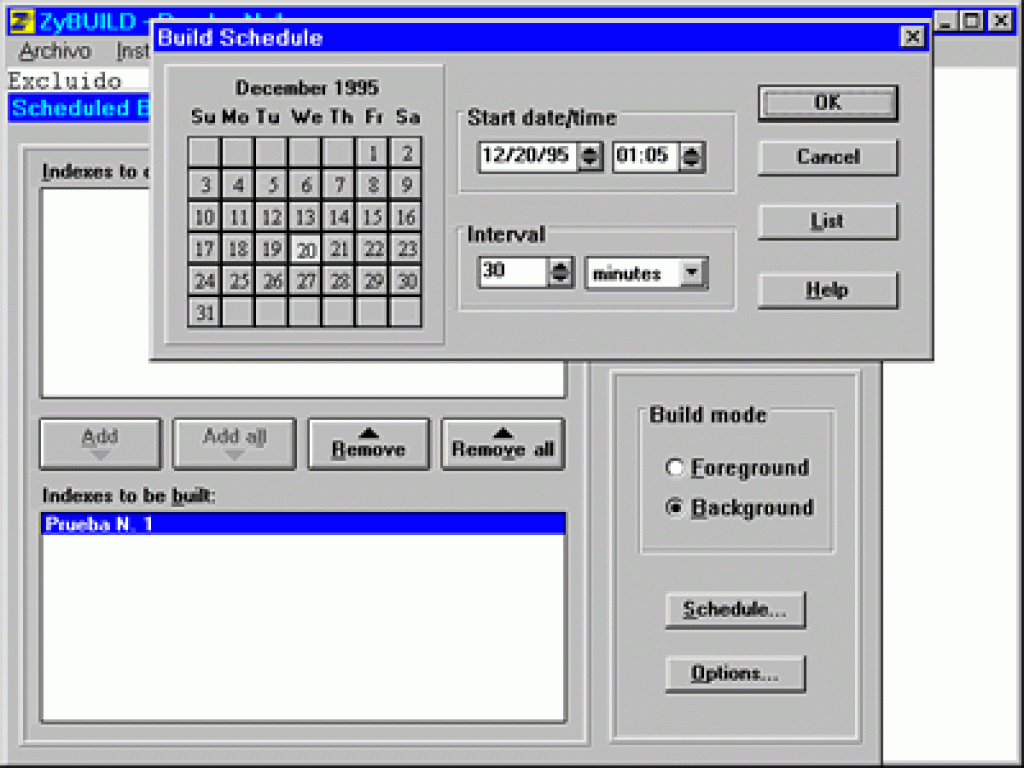
Las funciones del administrador permiten programar la indización en un módulo que, sorprendentemente, no han llamado agente.
Para crear una base de datos con ZyIndex sólo es necesario seleccionar uno o más directorios, especificar los archivos que formarán parte del índice (que pueden ser todos, sin más) e indicar, optativamente, los archivos excluidos, y el programa creará los índices necesarios para poder recuperar documentos según su contenido real, y no únicamente por datos tales como el nombre del archivo o su fecha de creación.
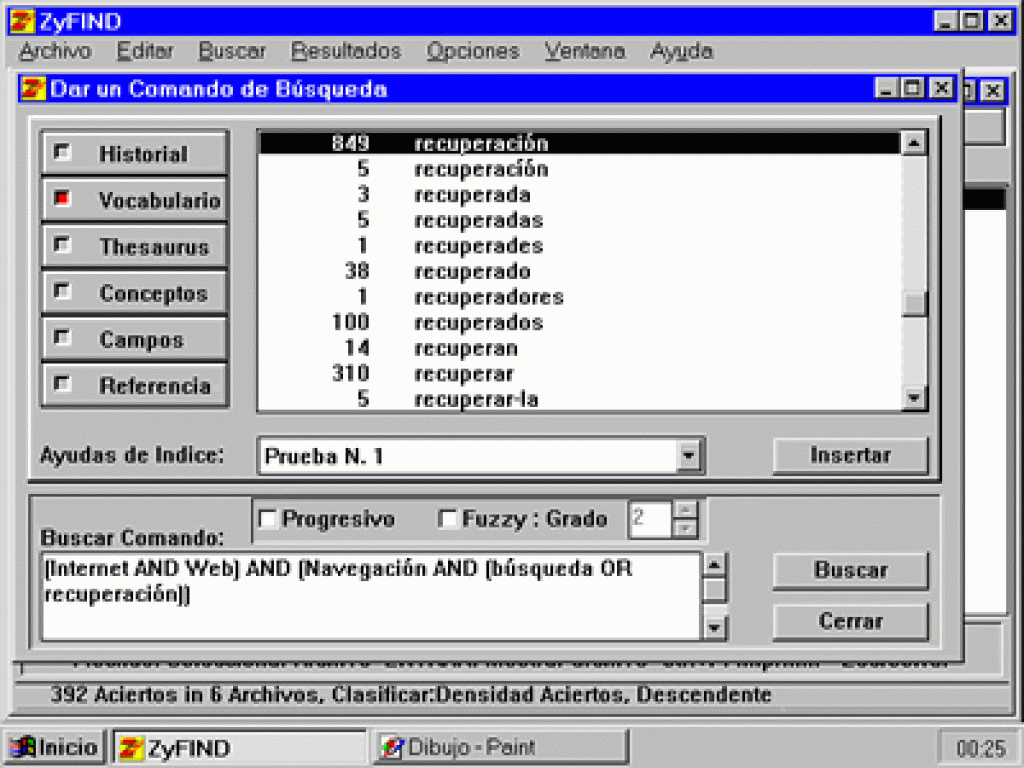
Se puede consultar en índice invertido creado por ZyIndex y ver la frecuencia de los términos en la base de datos.
Indización automática
La idea básica de la que parten programas como ZyIndex es que, en el contexto de grandes volúmenes de información, puede descubrirse cuáles son los documentos que tratan sobre determinado tema utilizando como pistas las propias palabras (todas) que contienen los documentos.
Esta tecnología, conocida por el nombre de full-text o indización de texto completo, pretende sustituir o complementar, según los casos, a la indización intelectual, basada en la asignación manual de descriptores y/o códigos de clasificación a cada documento a fin de identificar su tema o contenido.
Sin embargo, la experiencia demuestra reiteradamente que, sin indización intelectual, la eficacia de estos programas es relativa, y en concreto depende del tipo de documentos indizados, de la cantidad de información lingüística que emplean los motores de indización y del lenguaje de interrogación, así como de los algoritmos de cálculo de relevancia que incorporan.
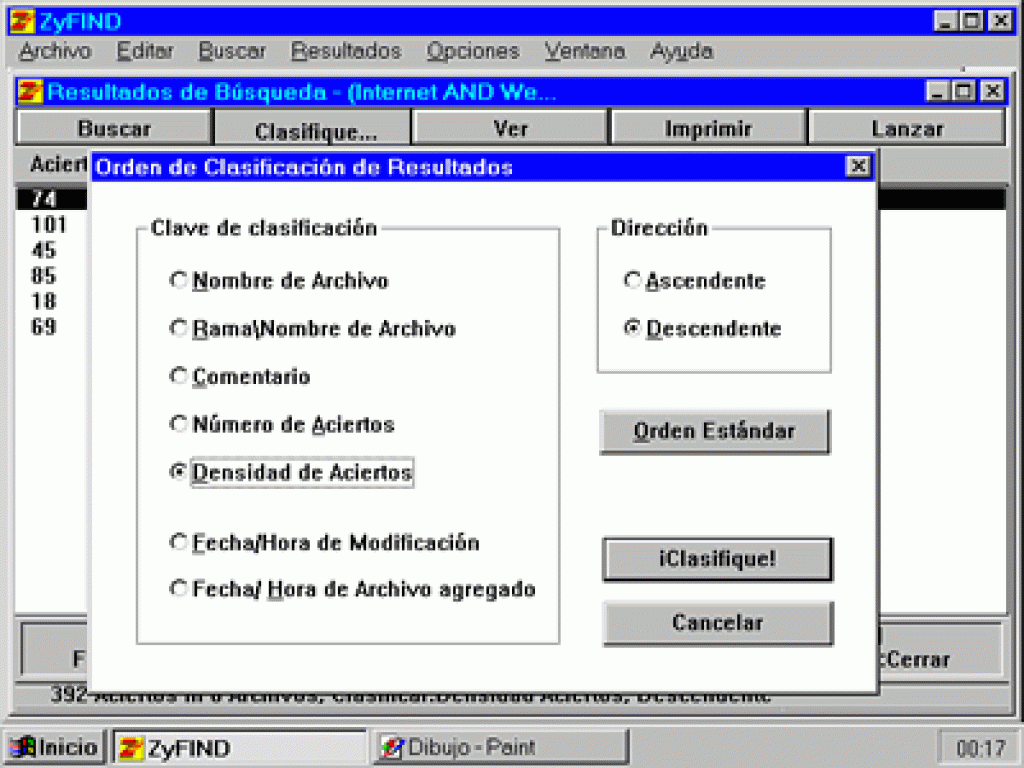
ZyIndex permite seleccionar diversas opciones de ordenación, dos de ellas basadas en el número de ocurrencias (aciertos)
En particular, documentos que utilizan un lenguaje muy variado y creativo, como es el caso de la información periodística, se prestan mucho peor a este tipo de indización que los documentos que utilizan un lenguaje más restringido, como informes técnicos o documentos ofimáticos, como saben bien todos cuantos hayan realizado búsquedas en Internet, donde lo que impera es, salvo excepciones recientes, la indización automática, con el consiguiente resultado de que la búsqueda suele ser bastante ruidosa.
En algunas ocasiones, pese a todo, no hay mucha posibilidad de elección y, por motivos económicos, de tiempo o por ambos, sólo es posible utilizar la indización automática, proporcione o no los mismos resultados que se conseguiría con una indización intelectual.
En este sentido, en la salida de la información, algunos de estos programas, tal como hace ZyIndex, no se limitan a entregar al usuario una lista de los documentos recuperados sino que la presentan ordenada por su grado de relevancia, intentando de ese modo compensar el ruido de algunas respuestas.
La relevancia se calcula normalmente por las frecuencias absolutas y relativas con que aparecen las palabras en los documentos recuperados. O sea, estos métodos no se basan en el sentido de las palabras, sino en la simple frecuencia de ciertas cadenas de caracteres, con lo cual a veces los resultados son sorprendentemente inexactos, aunque en general funciona bien.
Conviene no olvidar que la ordenación de los resultados por grado de relevancia es independiente tanto del estilo de indización (automático o intelectual), como de la forma de realizar las preguntas (con o sin operadores booleanos), ya que el único requisito para poder aplicarla con éxito es que los documentos de la base de datos sean de texto completo, o que contengan por lo menos un resumen amplio.
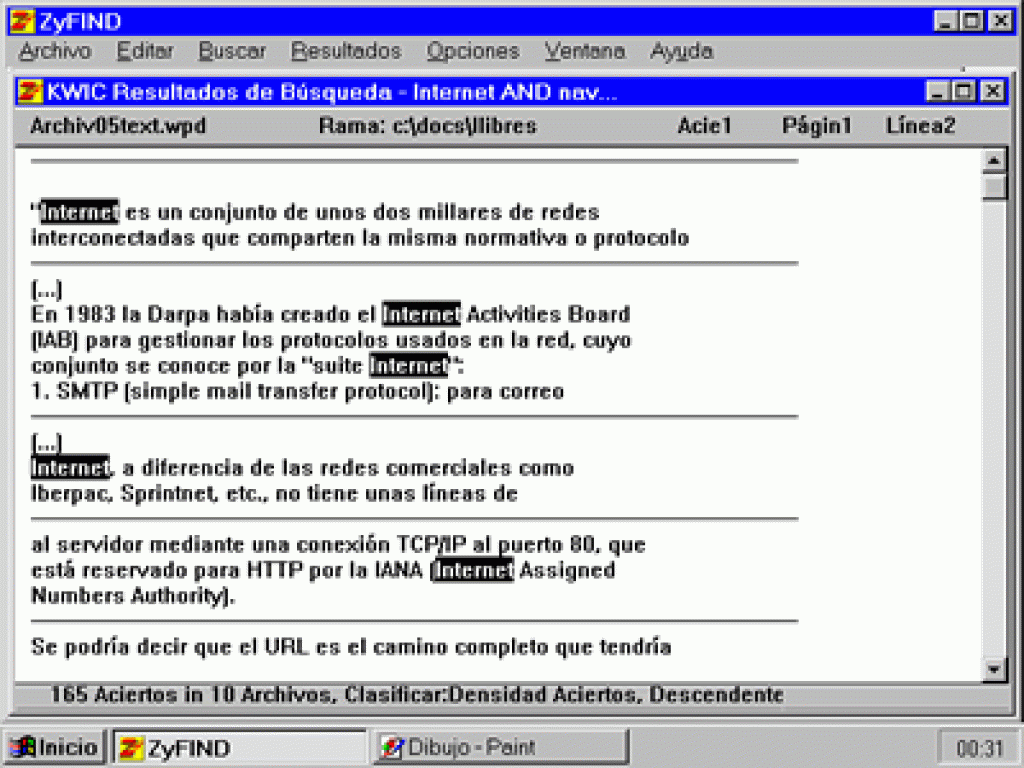
Una de las salidas de programa consiste en un índice KWIC, es decir, en el contexto que rodea a los términos de búsqueda
Búsqueda de la información
Una vez creados los índices, es posible localizar documentos con ZyIndex indicando simplemente una palabra o una frase de búsqueda y, como resultado, el programa entrega una lista de todos los documentos que contienen esa palabra.
Los resultados pueden ordenarse por diversos criterios, entre ellos por dos formas de relevancia:
- La primera calcula la frecuencia absoluta de los términos en cada documento. En teoría, cuantas más veces aparezca una palabra o frase en un documento, más aumenta la probabilidad de que el documento sea relevante.
- La segunda calcula la frecuencia relativa (densidad) de los términos.
Desde la ventana de resultados se puede conmutar a la ventana de visualización del documento, que muestra el resultado en texto simple, sin atributos tipográficos ni formato. En esta misma ventana de visualización pueden realizarse las opciones básicas de navegación, tales como ver las siguientes ocurrencias (el contexto donde ocurren las palabras de búsqueda) y los documentos siguientes y anteriores de la lista, así como activar la aplicación con la que se ha creado el documento.
Lenguaje de interrogación
Cuando una simple palabra o frase no basta para obtener listas selectivas de documentos, ZyIndex ofrece una amplia batería de recursos alternativos. En primer lugar, permite utilizar operadores booleanos OR, AND y NOT para combinar dos o más palabras y expresar así necesidades de información más complejas. La forma general es: <término 1> operador <término 2>, incluso combinando más de un operador y utilizando paréntesis para indicar la precedencia y el sentido de las operaciones.
Los truncamientos suelen figurar en casi todos los lenguajes documentales, pero no todos permiten, como ZyIndex, truncar a izquierda (*matico) y a ambos lados (*matic*), utilizar uno o más comodines, expresados mediante el símbolo «?» y con el mismo sentido que en el sistema operatido DOS, es decir, sustituyendo caracteres individuales. Por ejemplo, inform* recupera informe, informa, información, informático, etc. En cambio, inform?, sólo recupera informe, informa, etc.
Respecto a los operadores de proximidad, en ZyIndex, se puede construir la siguiente ecuación de búsqueda: proximidad P/10 ecuación, para indicar al sistema que recupere todos los documentos donde, en cualquier contexto, el término proximidad preceda al término ecuación, y que haya, como máximo, 10 palabras entre ellos. De este modo, este artículo sería recuperado, pues dicha condición se da, por ejemplo, al comienzo de este párrafo, ya que sólo siete palabras separan a ambos términos de la ecuación y aparecen en el orden prefijado.
En este sentido, el lenguaje de ZyIndex ofrece las herramientas fundamentales de los lenguajes de búsqueda documentales y además enriquecidas con numerosas opciones que no siempre suelen encontrarse en otros programas y que aquí no detallamos. Además, ZyIndex proporciona algunas posibilidades de recuperación que son, que nosotros sepamos, exclusivas.
Entre otras comentaremos dos por su interés:
- En primer lugar el operador que ZyIndex llama TO. Se utiliza entre dos términos, T1, T2, junto con un tercer término T3, en la siguiente forma: T1 TO T2 (T3), y significa literalmente: «busca documentos donde aparezca el término T3 situado entre los términos T1 y T2«.
Por ejemplo, la ecuación del lenguaje ZyIndex: expertos TO neuronales (redes) serviría para recuperar «sistemas expertos basados en redes neuronales», o «sistemas expertos que utilizan tecnología de redes neuronales», pero no «redes de expertos en enfermades neuronales», etc.
- El segundo operador que queremos destacar es el denominado Quorum, que especifica cuántos de los términos de búsqueda, T1, T2, … TN, deben figurar en los documentos para que se consideren relevantes. La forma de uso del operador Quorum es la siguiente: N OF {T1, T2, …TN}.
Por ejemplo, si deseamos seleccionar documentos que hablen por lo menos de tres de un grupo de países, pero no importa de cuáles, podríamos plantear la siguiente ecuación: 3 OF {Francia, Alemania, España, Inglaterra, Italia, Portugal, Grecia}. Los documentos que hablen de tres de los países mencionados, cualquiera de ellos, serán recuperados, pero no si hablan nada más de dos o de uno solo de ellos.
Que recordemos, sólo hemos visto alguna variante de este operador en ciertos buscadores web o en sistemas de interrogación de bases de datos de acceso público (online), pero no en programas para microordenadores. Aunque Notes (Lotus) posee un operador parecido (accrue) no produce exactamente el mismo resultado, ya que, de hecho, en Notes es una opción de cálculo de relevancia y no discrimina entre documentos, sino que otorga más peso a los que poseen mayor variedad de términos de la pregunta.
Diccionarios y complementos
ZyIndex permite utilizar diccionarios de palabras vacías y de sinónimos (thesaurus) para mejorar la calidad de los índices y el rendimiento de las operaciones de recuperación, así como establecer enlaces (nexos) entre un término o una zona de un documento y otro documento de texto o un fichero gráfico. Además, el usuario puede añadir notas a los documentos cuyo contenido también puede indizarse.
ZyIndex es una aplicación que está orientada a crear bases de datos de modo automático y sin otra intervención humana que indicar qué directorios indizar y cuándo poner al día el índice u otras tareas de simple mantenimiento, y por ello pone el acento en la rapidez de indización y en la potencia de su lenguaje de recuperación. Pero, por ese mismo motivo, no es posible utilizar el programa como una base de datos convencional, es decir, con utilización de campos, informes de salida y formularios de entrada de datos, aunque permite definir zonas del documento como campos para restringir las búsquedas.
Existen versiones del programa que pueden utilizarse como medio de publicación y distribución electrónica de documentos, tanto en disco óptico como a través de Internet, así como una versión (ZyImage) que puede controlar un escáner, más un programa de OCR (reconocimiento óptico de caracteres) y asociar imágenes a documentos de texto, y capturar documentos en papel y convertirlos en archivos ascii indizados.
ZyIndex está producido por ZyLab International, Inc., Gaithersburg, Maryland, EUA.
Distribuidor en España:
Microbridge Ibérica. Trav. de Gracia 29, 2º. 08021 Barcelona.
Tel.: +34-3-414 13 21; fax: 491 15 02
Precio: Una licencia, 89.900 PTA. ZyImage u otro número de licencias, consultar.
Lluís Codina
codina_lluis@fcsc.upf.es
—
Esta información se publicó en la revista Information World en Español (IWE), n. 44, mayo de 1996, pp. 20-22.
- Volver al índice de este número 44:
https://www.scimagoepi.com/information-world-en-espanol-iwe-numero-44-mayo-de-1996
- Volver a la página principal de Information World en Español (IWE):
https://www.scimagoepi.com/information-world-en-espanol-iwe